Google画像検索[吹雪]。いつの間にかに大半が自然の吹雪になってた。いつからだろ。 pic.twitter.com/YpiyC9K2Xf
— 辻正浩 | Masahiro Tsuji (@tsuj) 2022年4月6日
ということで調べてみました。
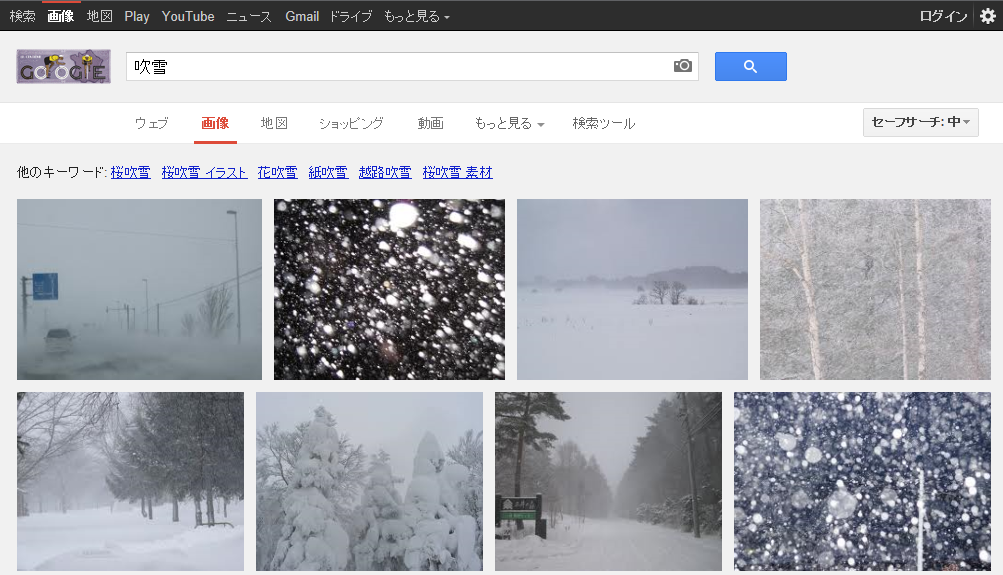

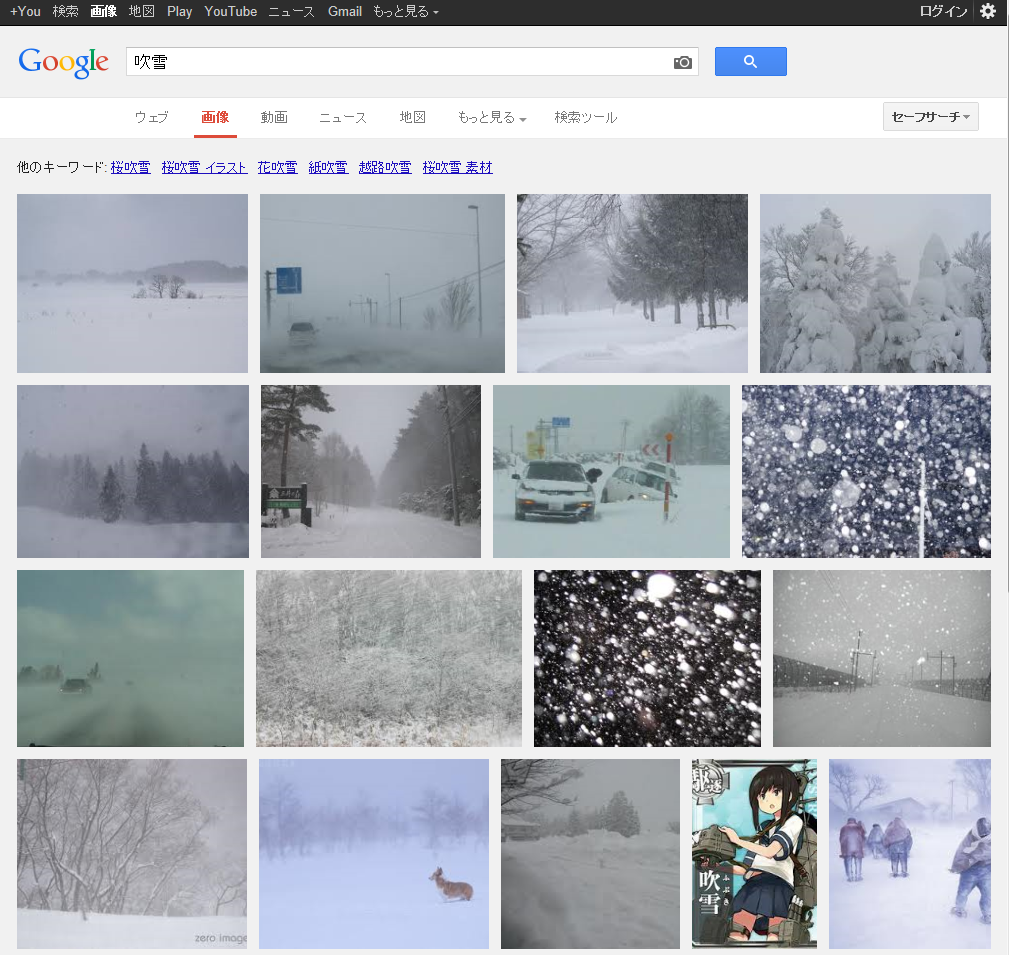

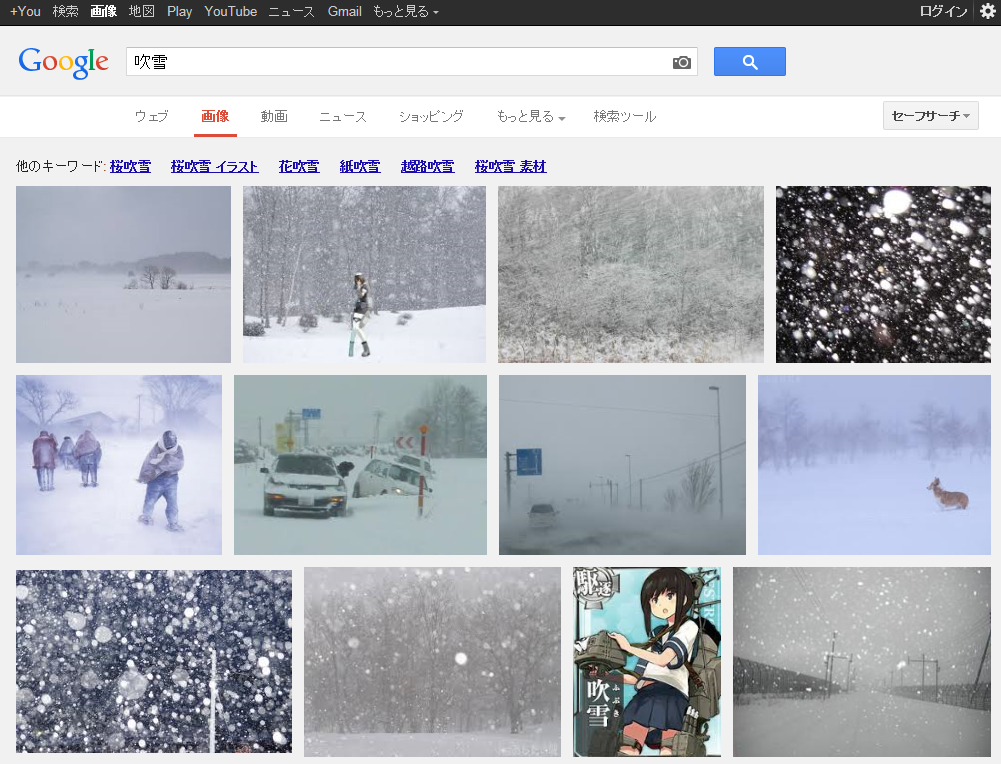
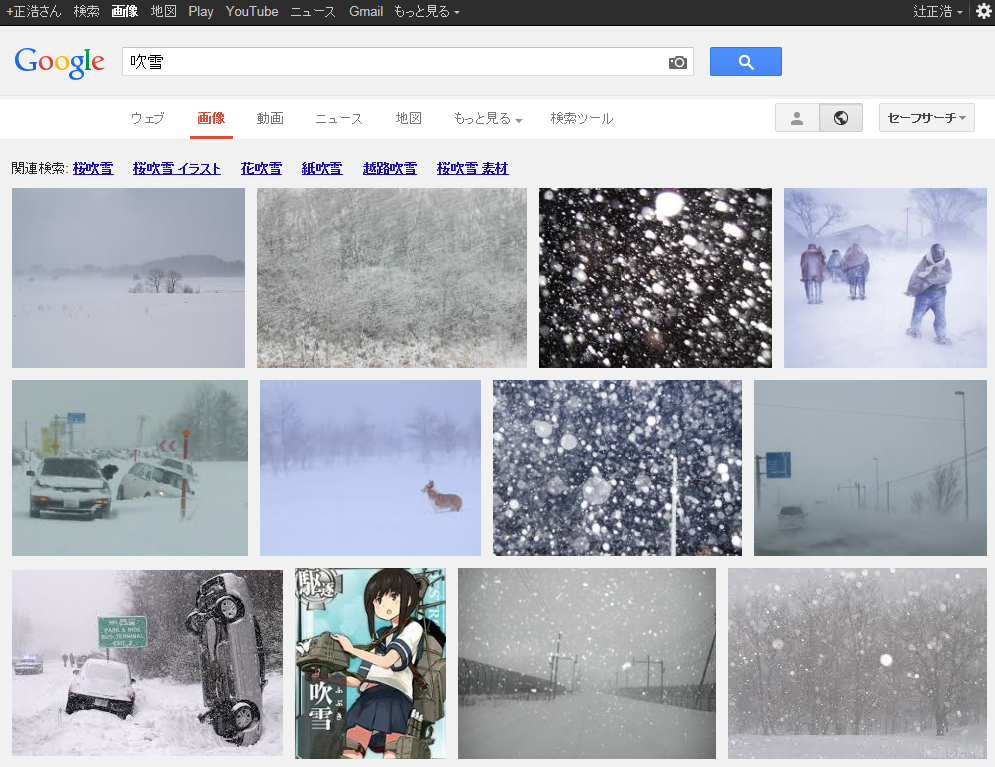
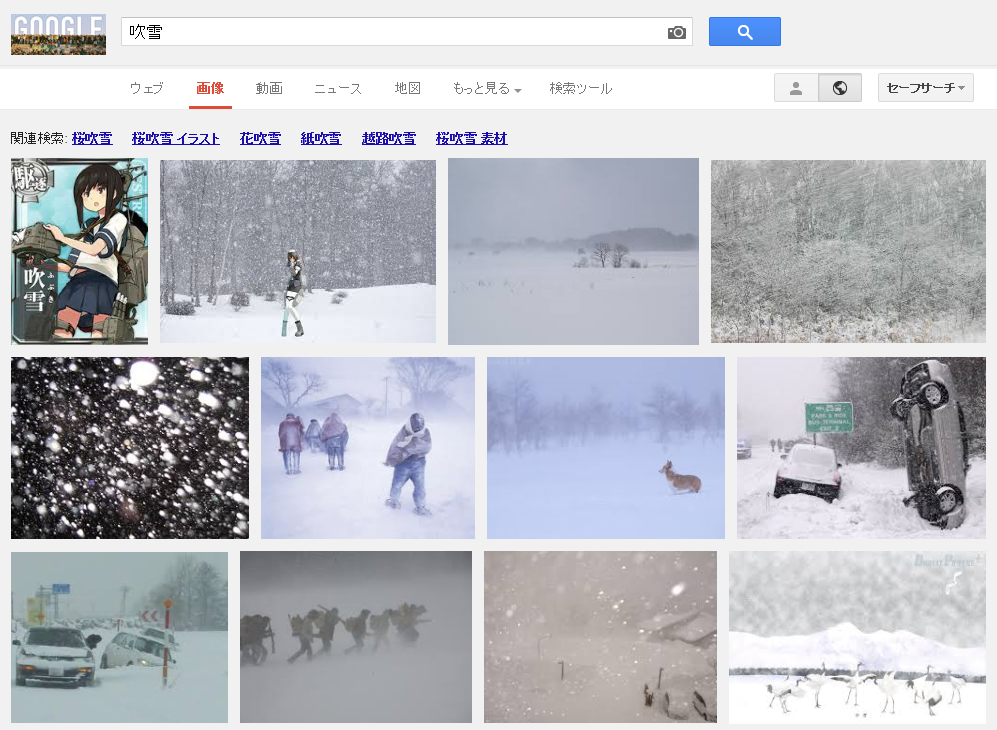

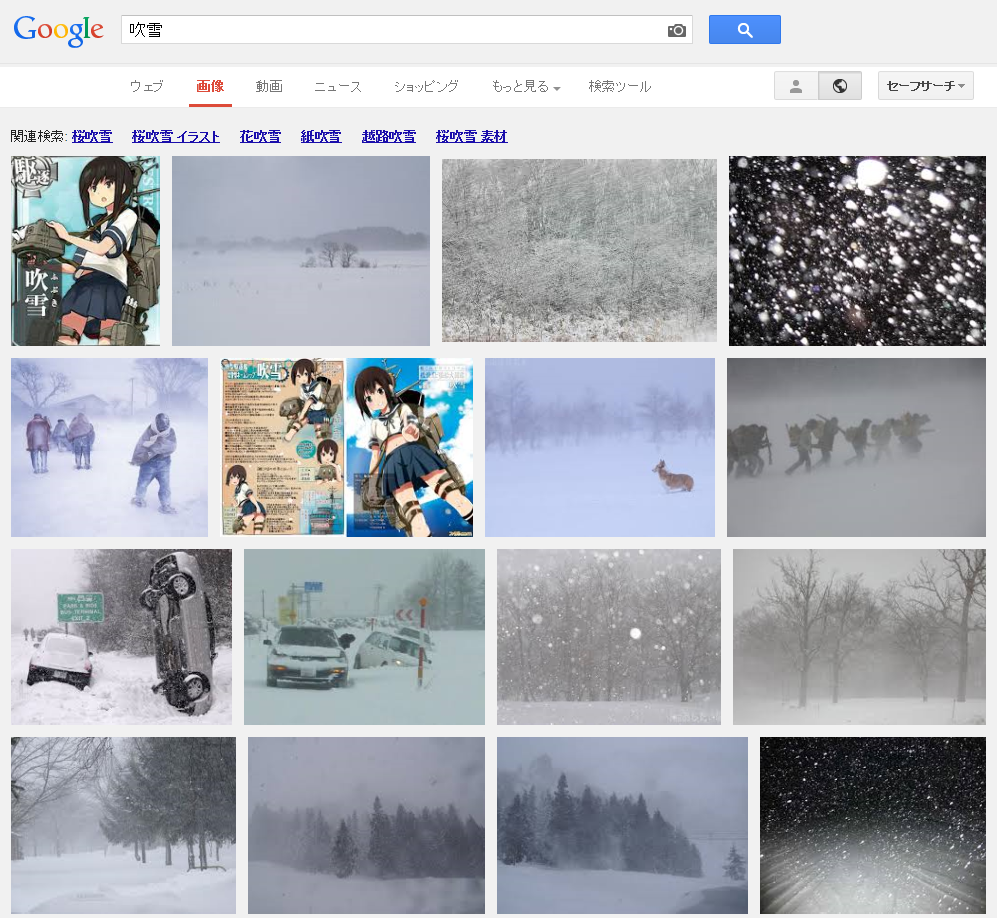
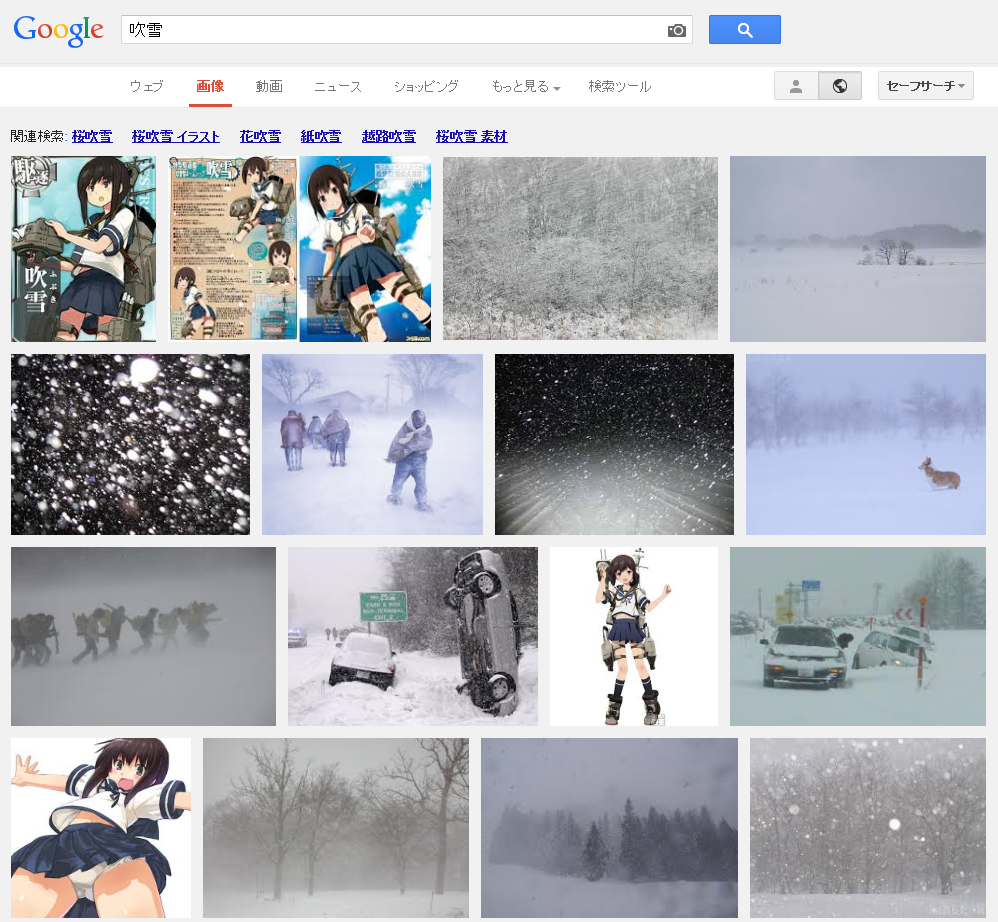
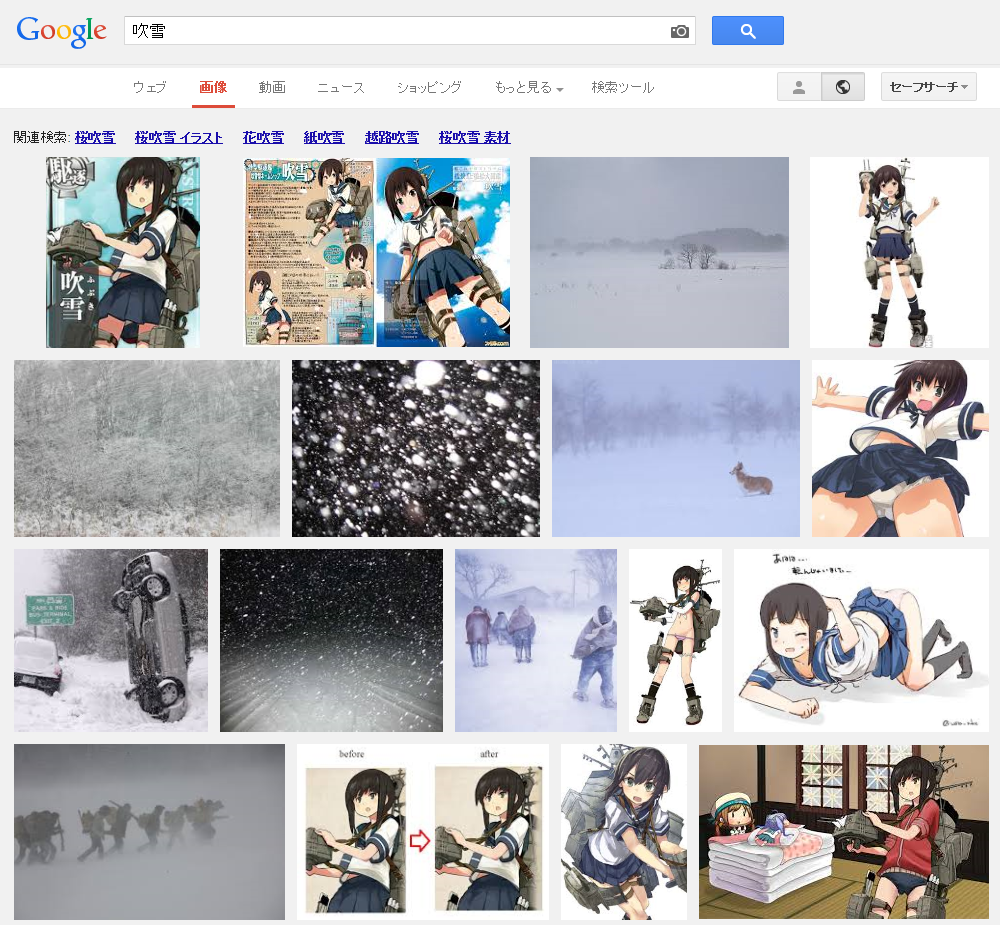
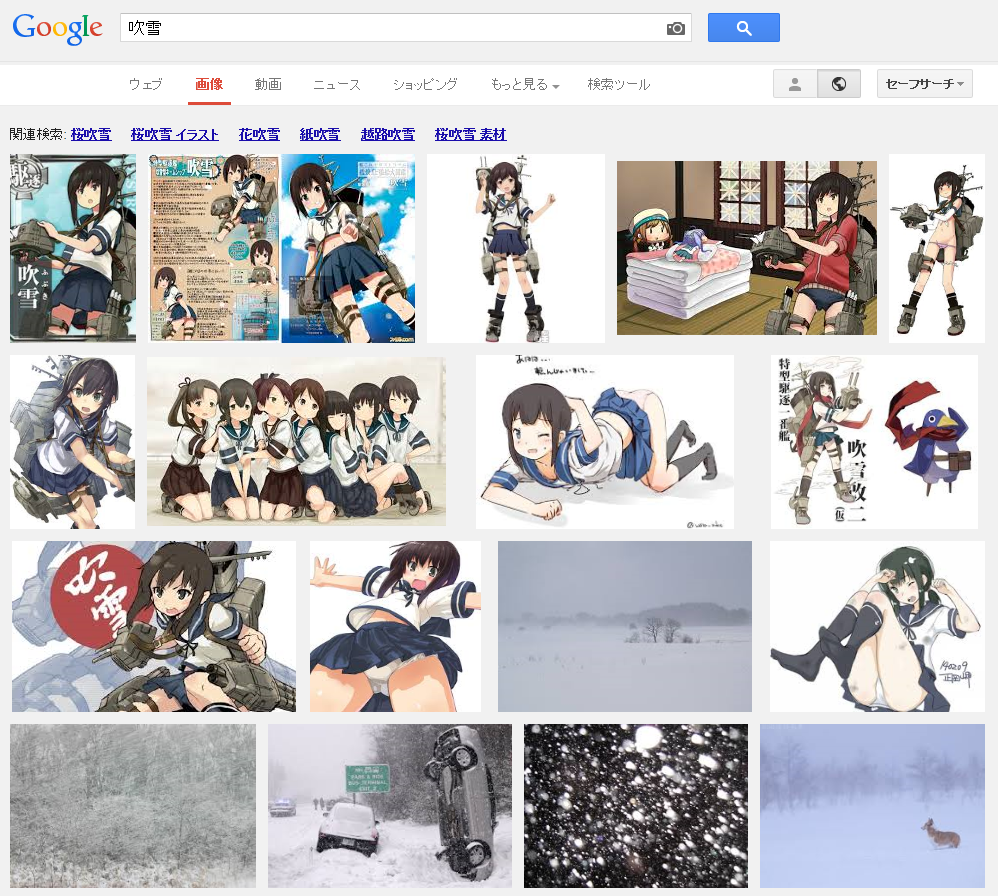
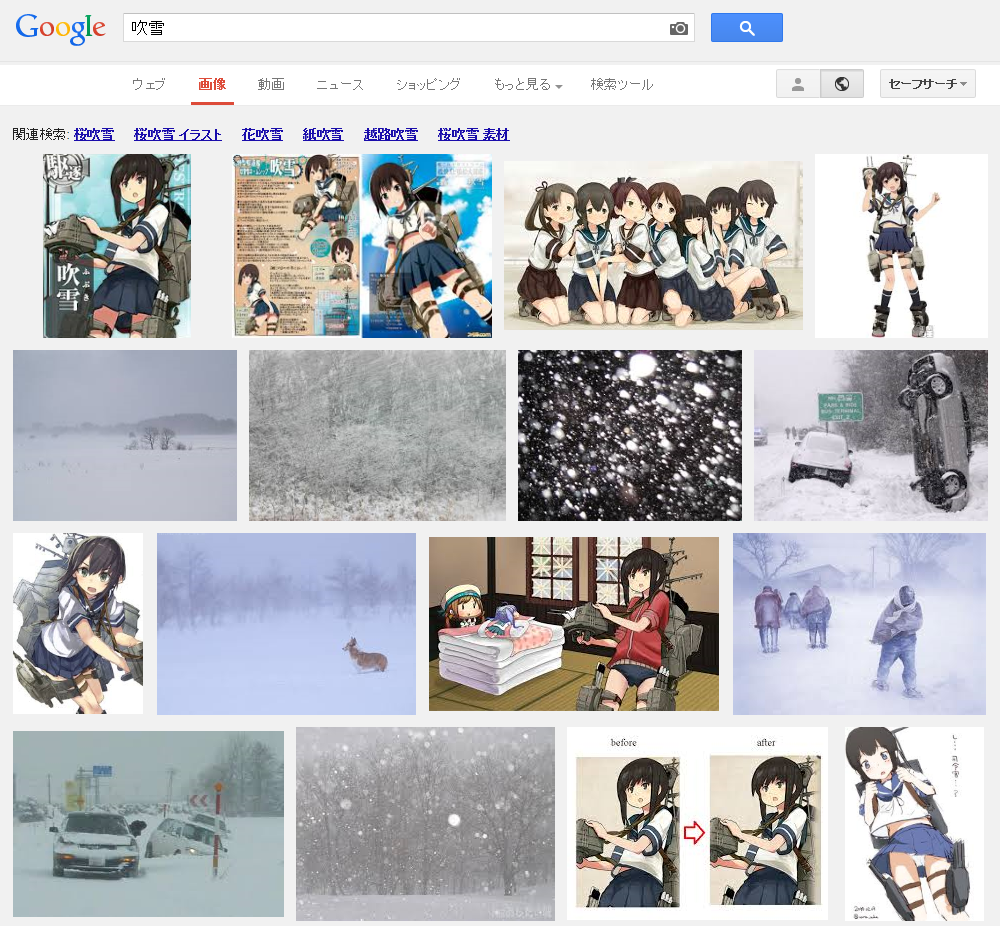
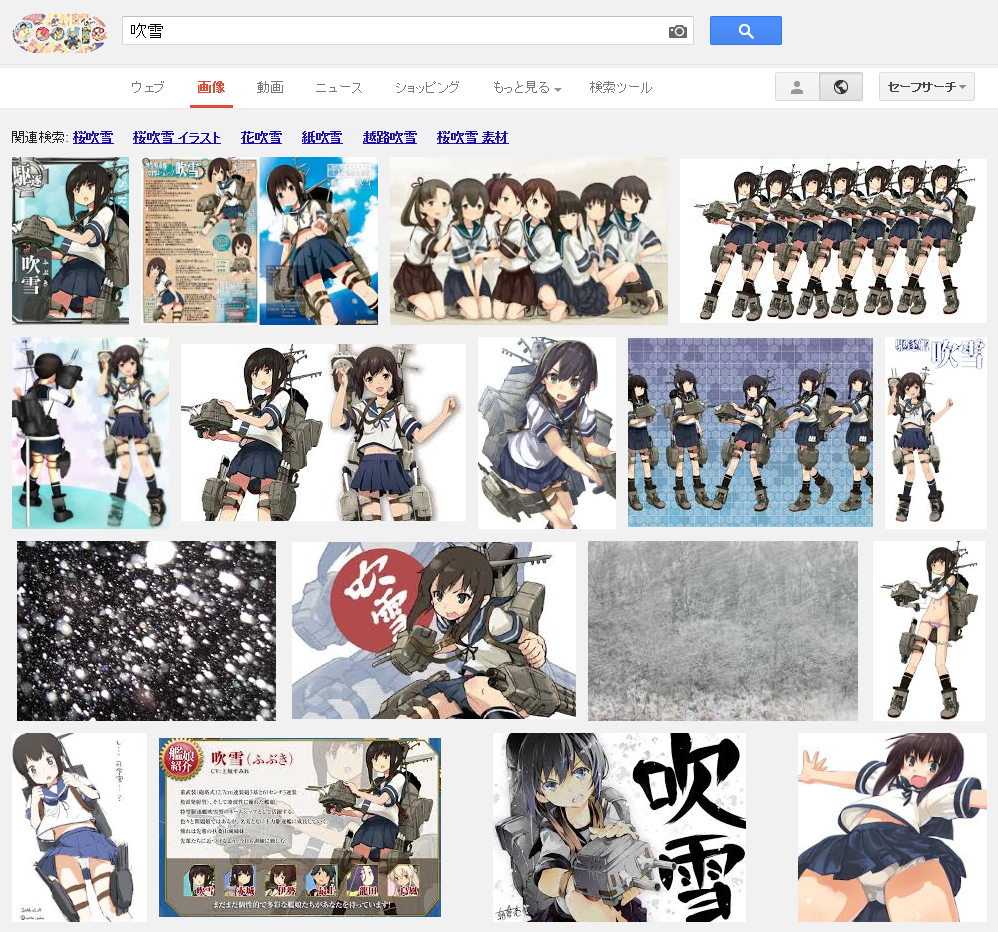
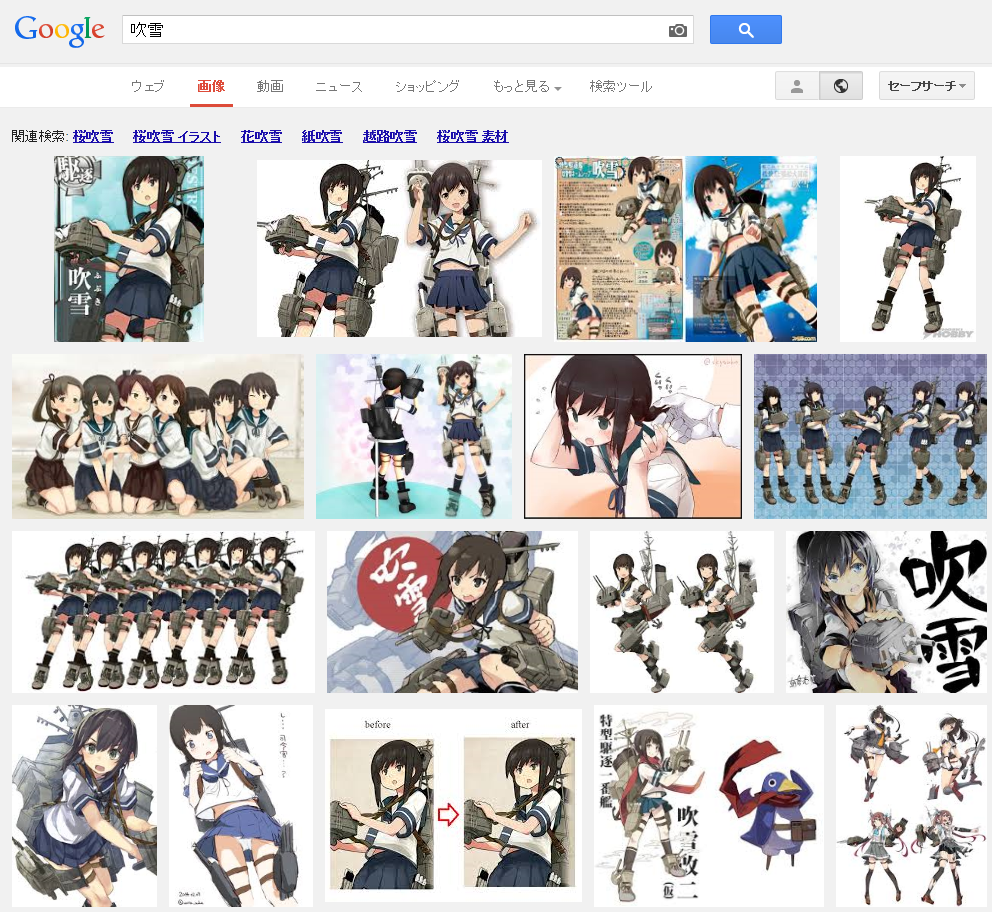
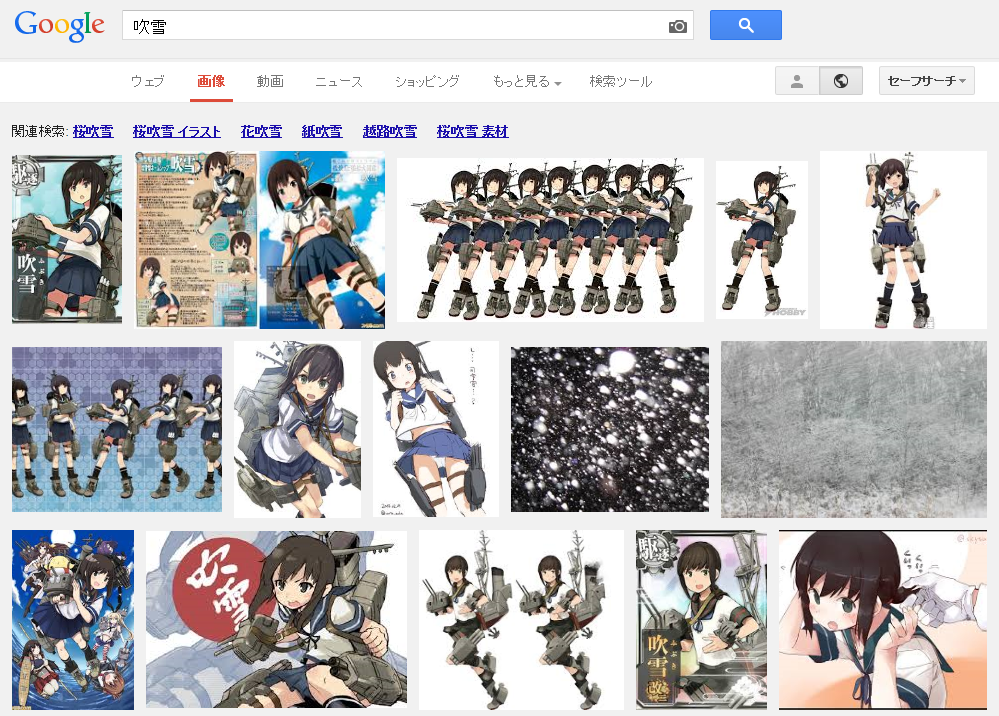
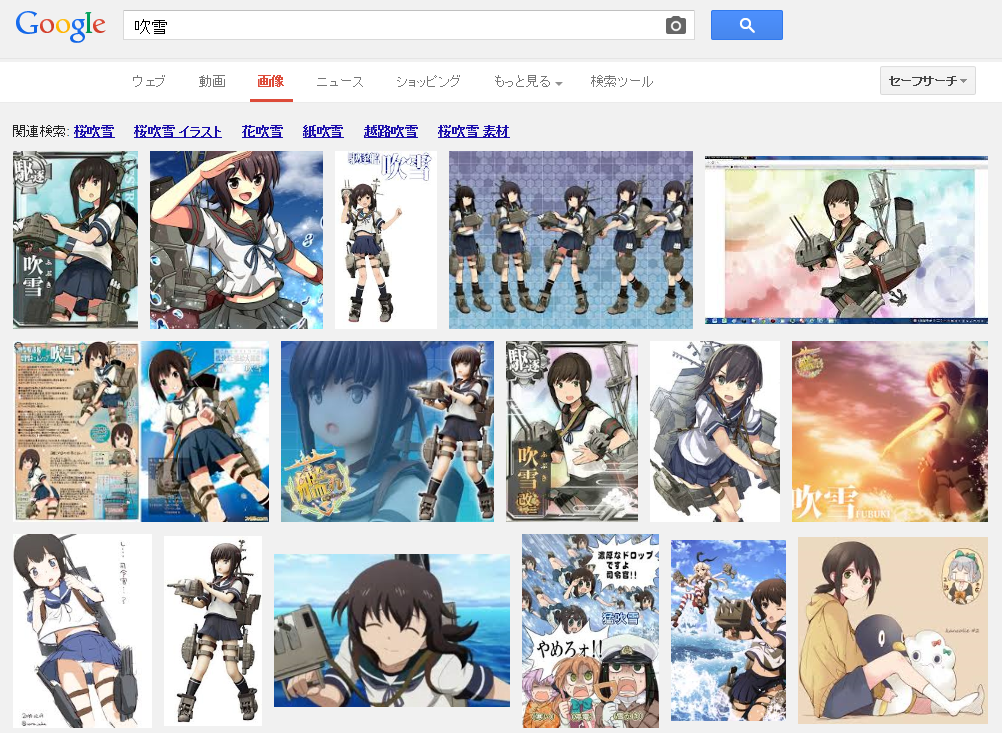
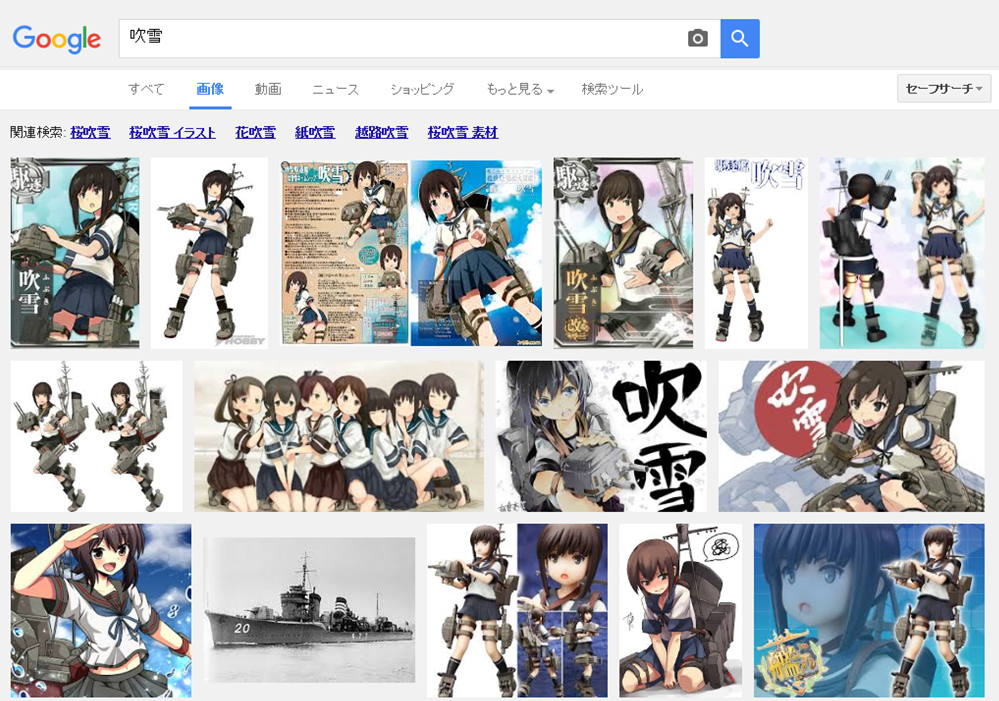
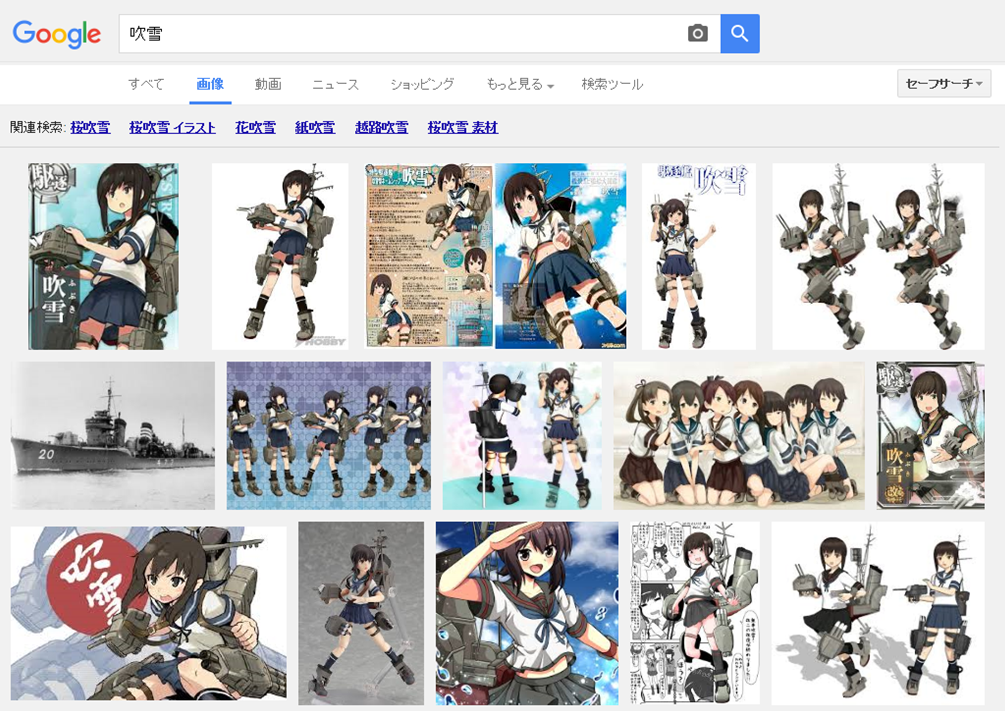
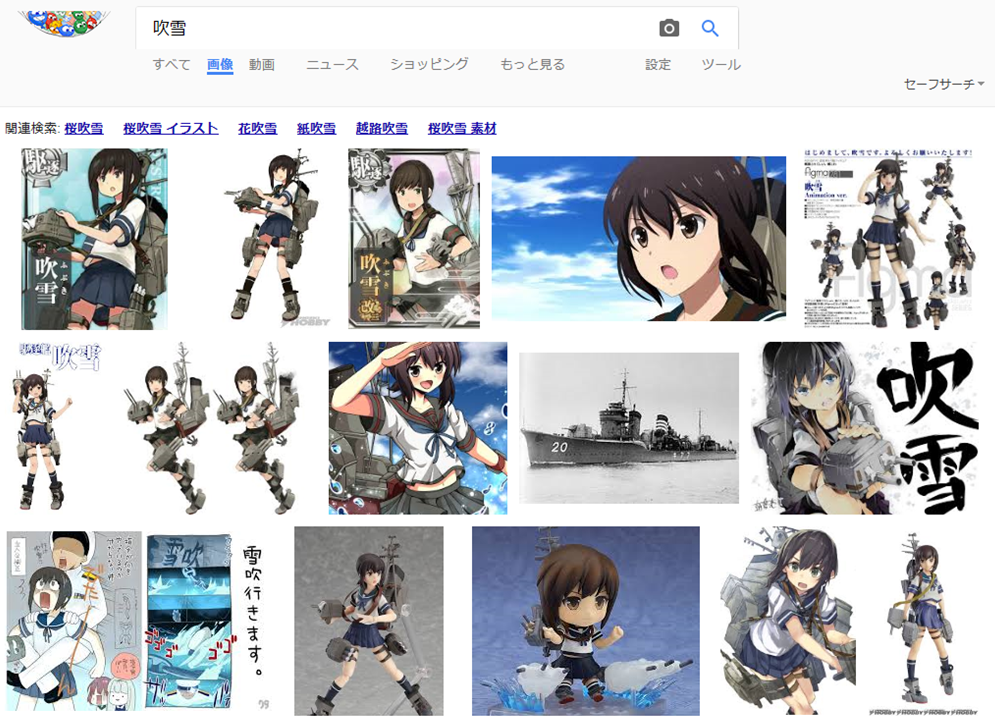
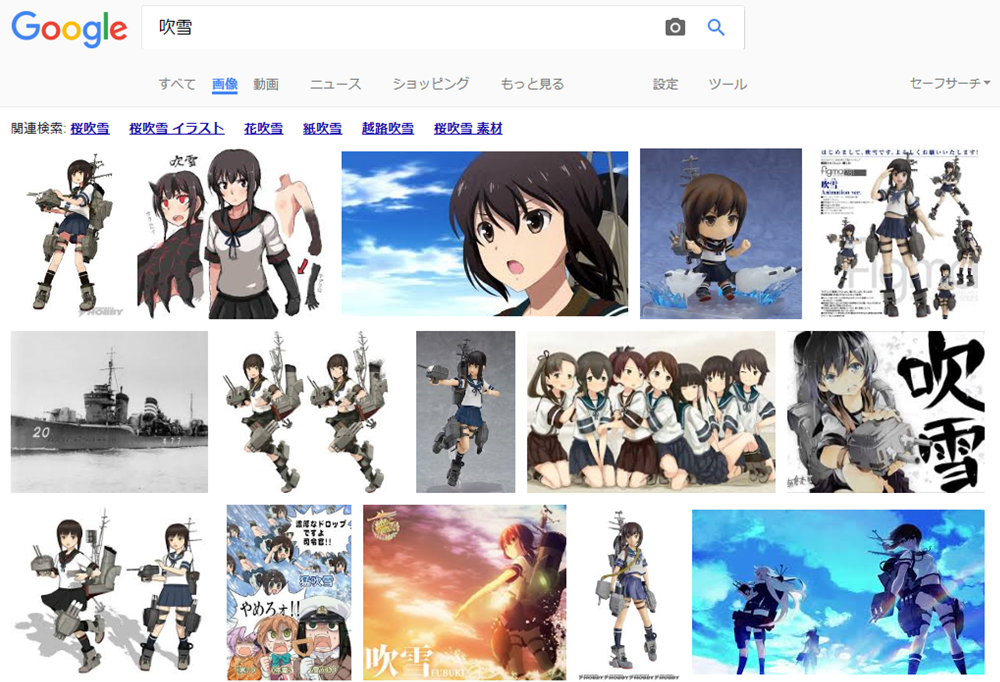
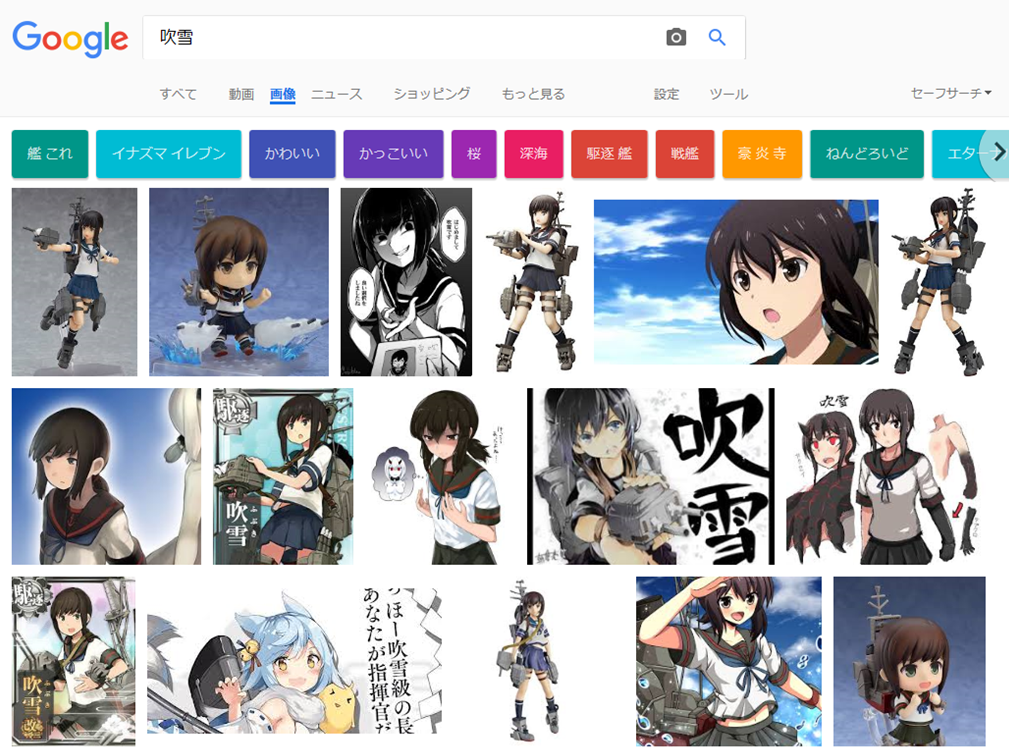
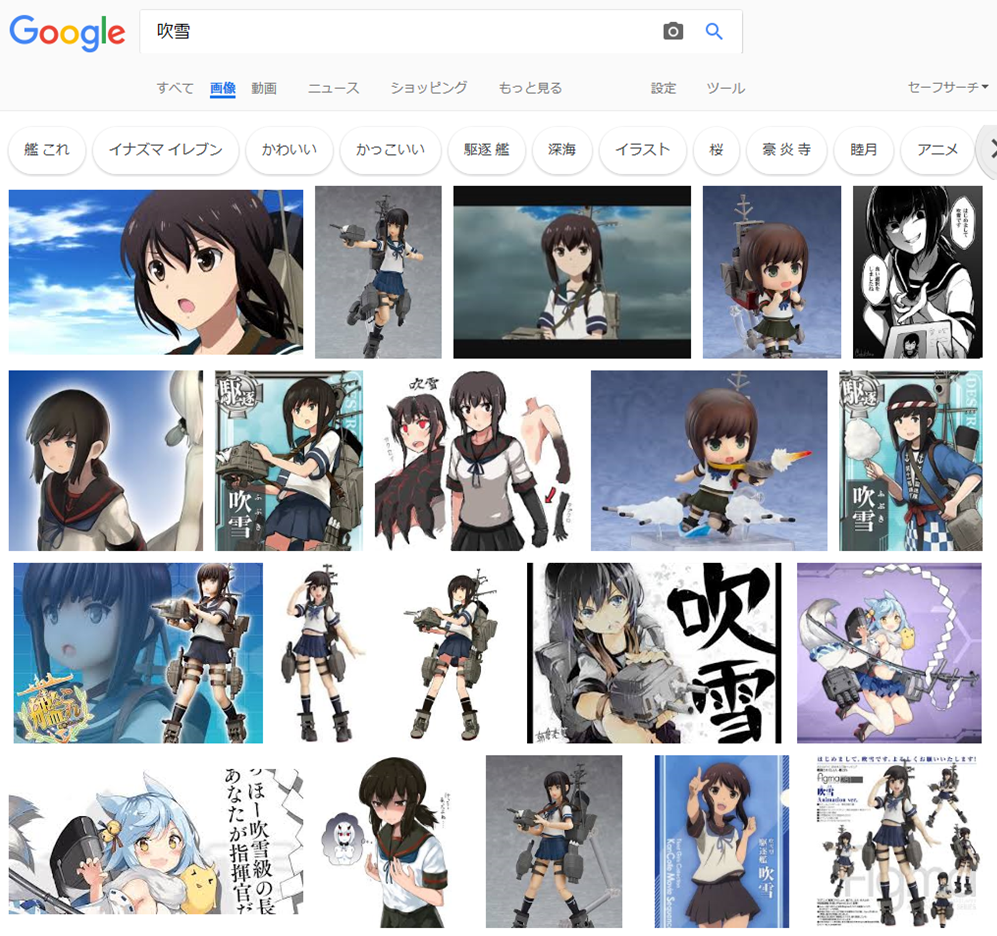




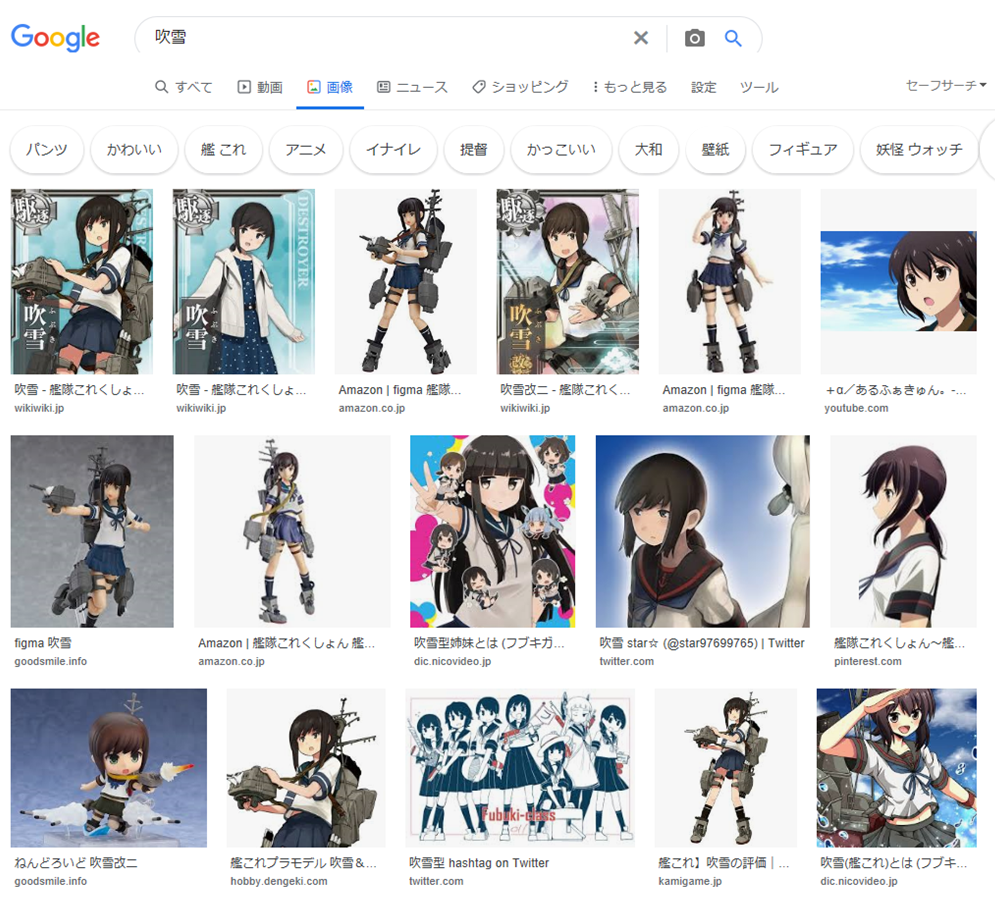
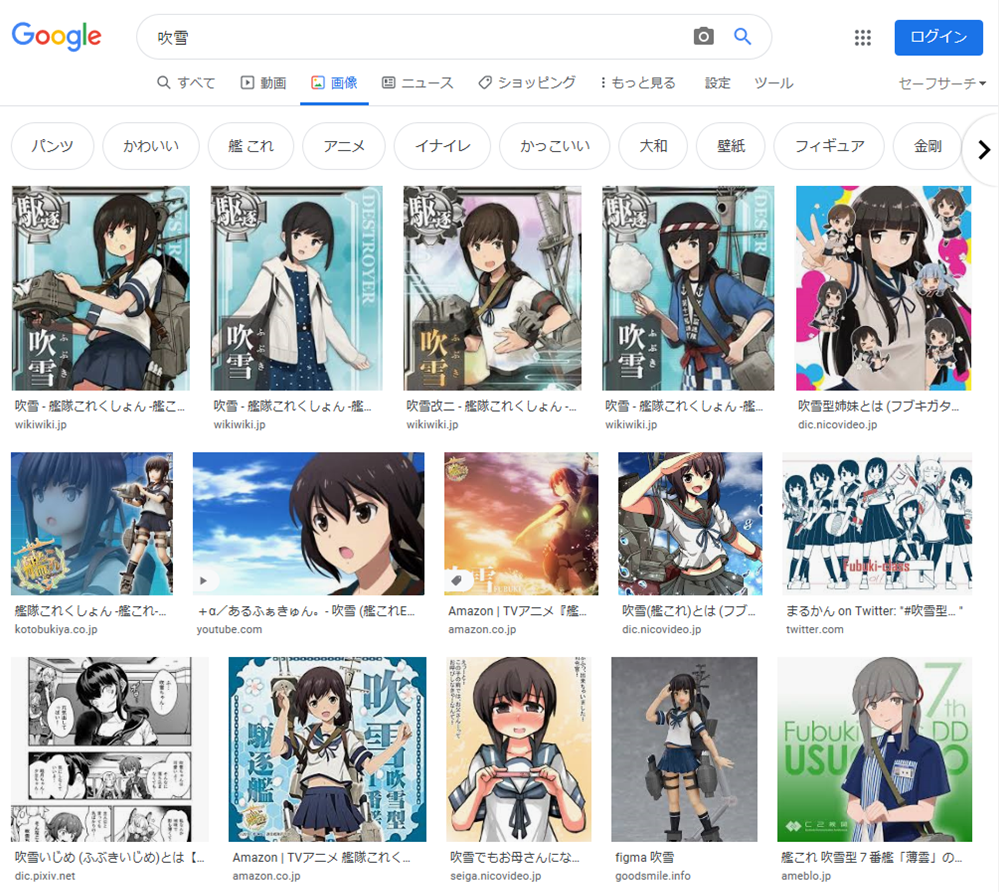
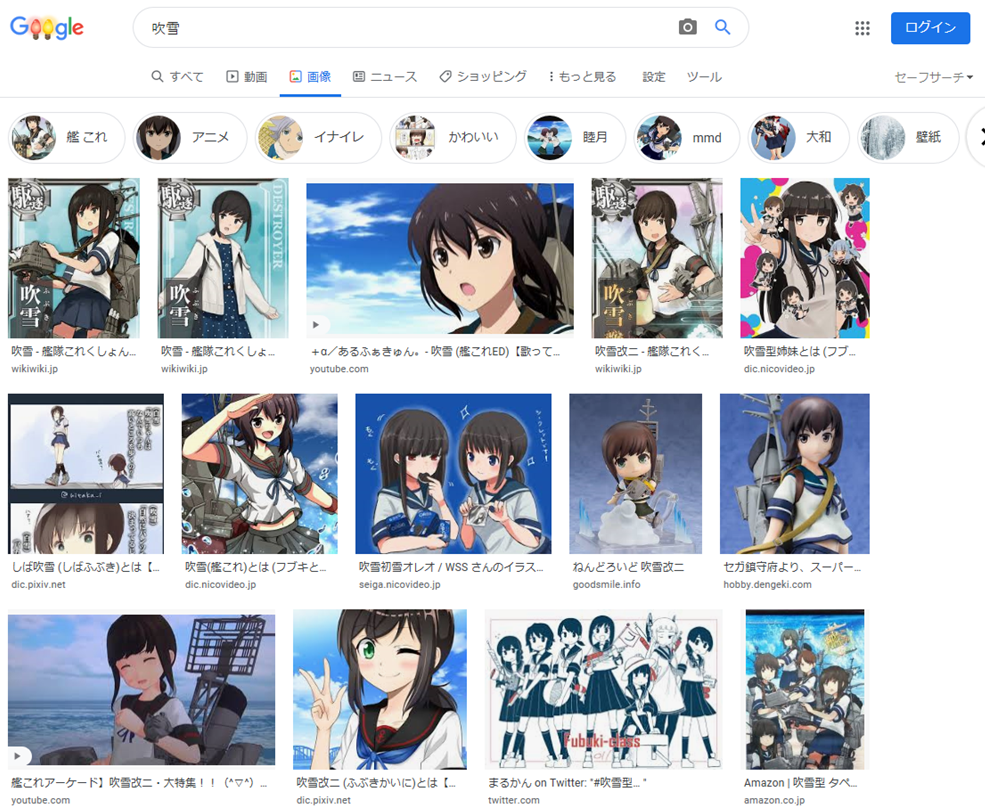
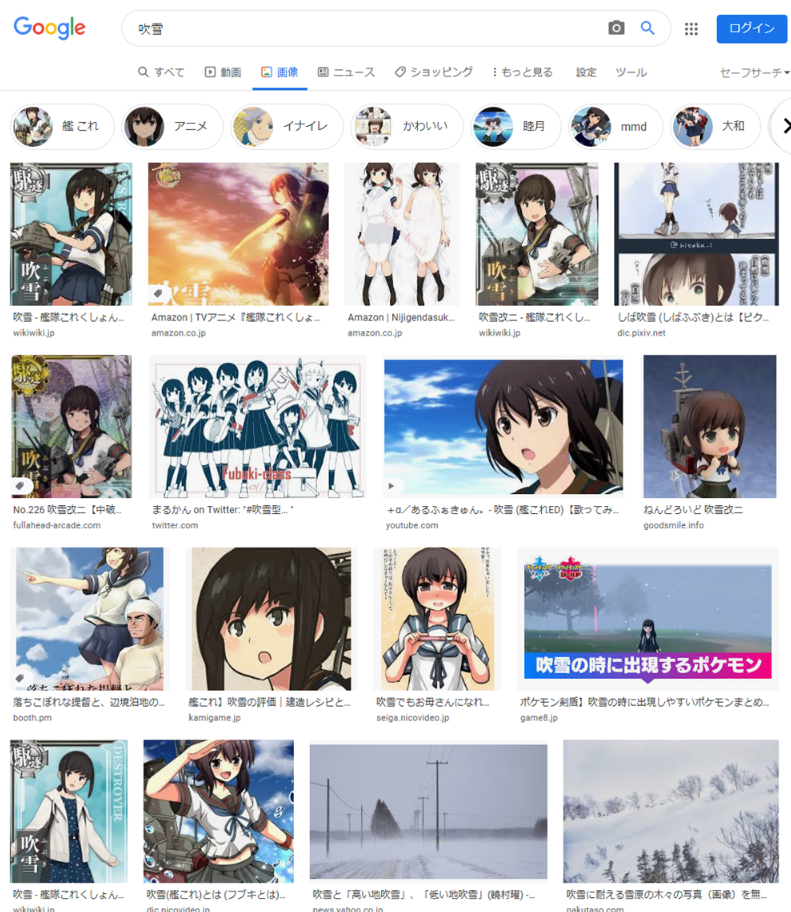
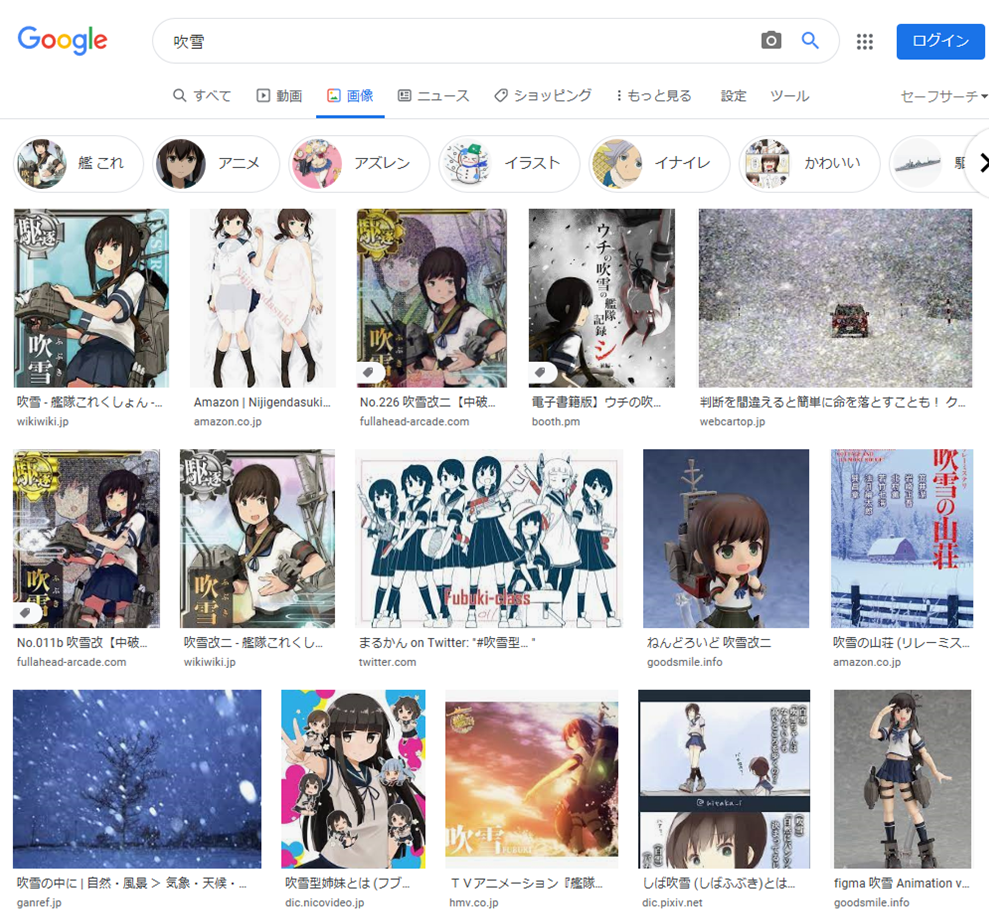
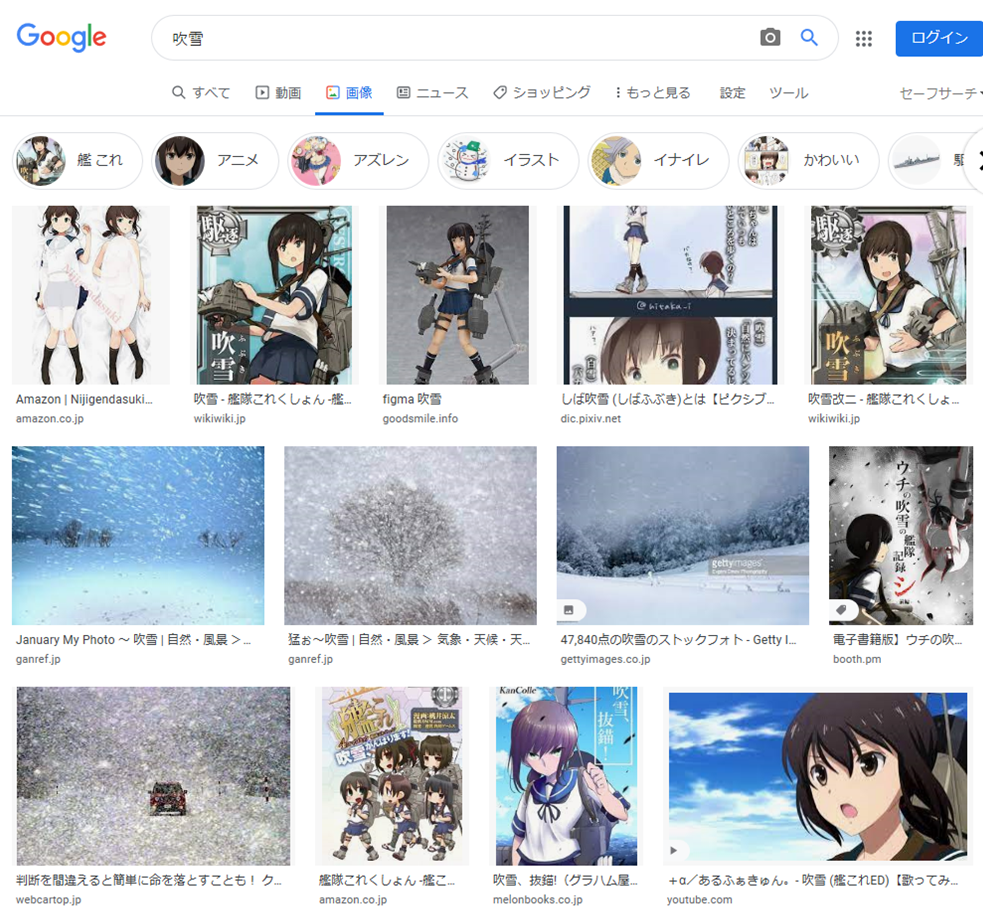
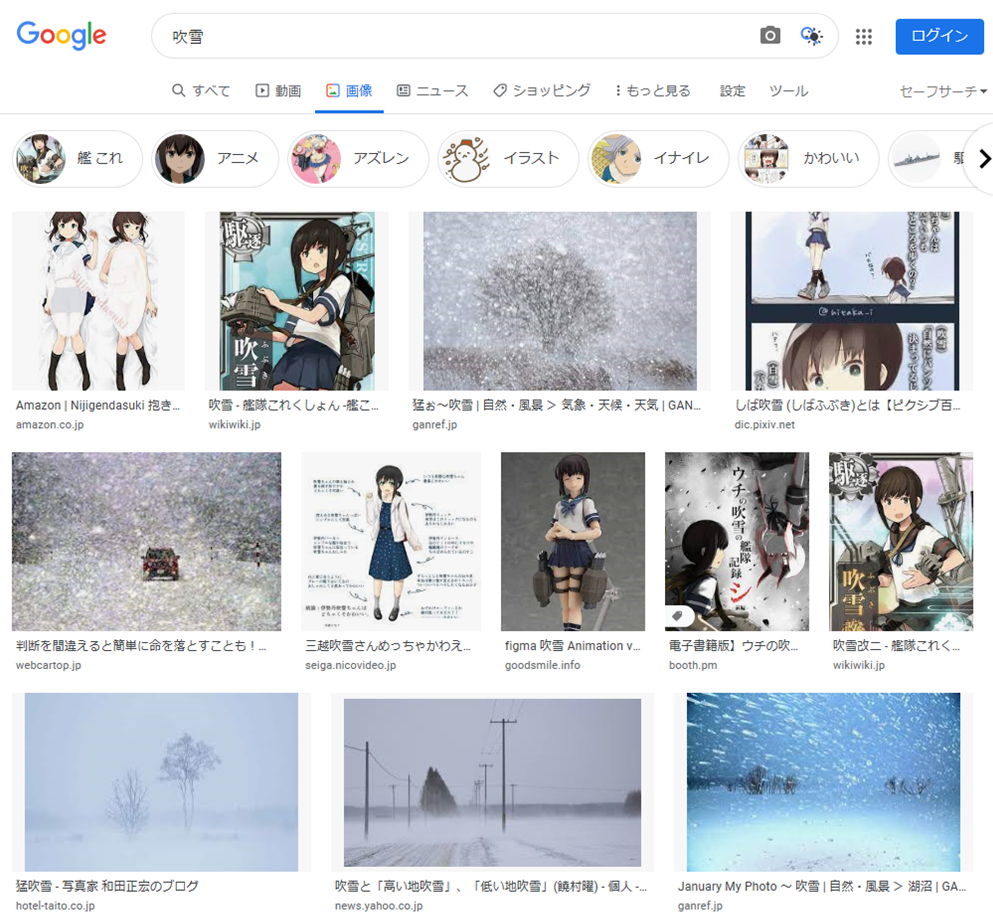
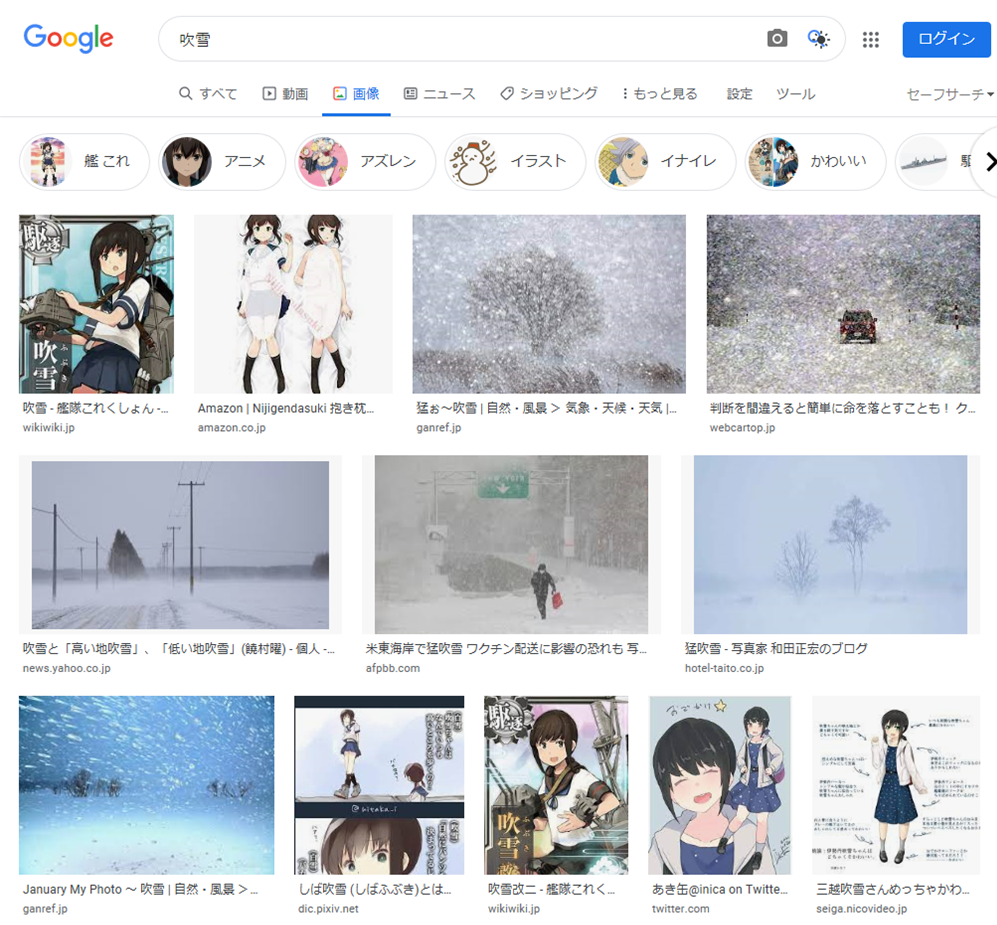
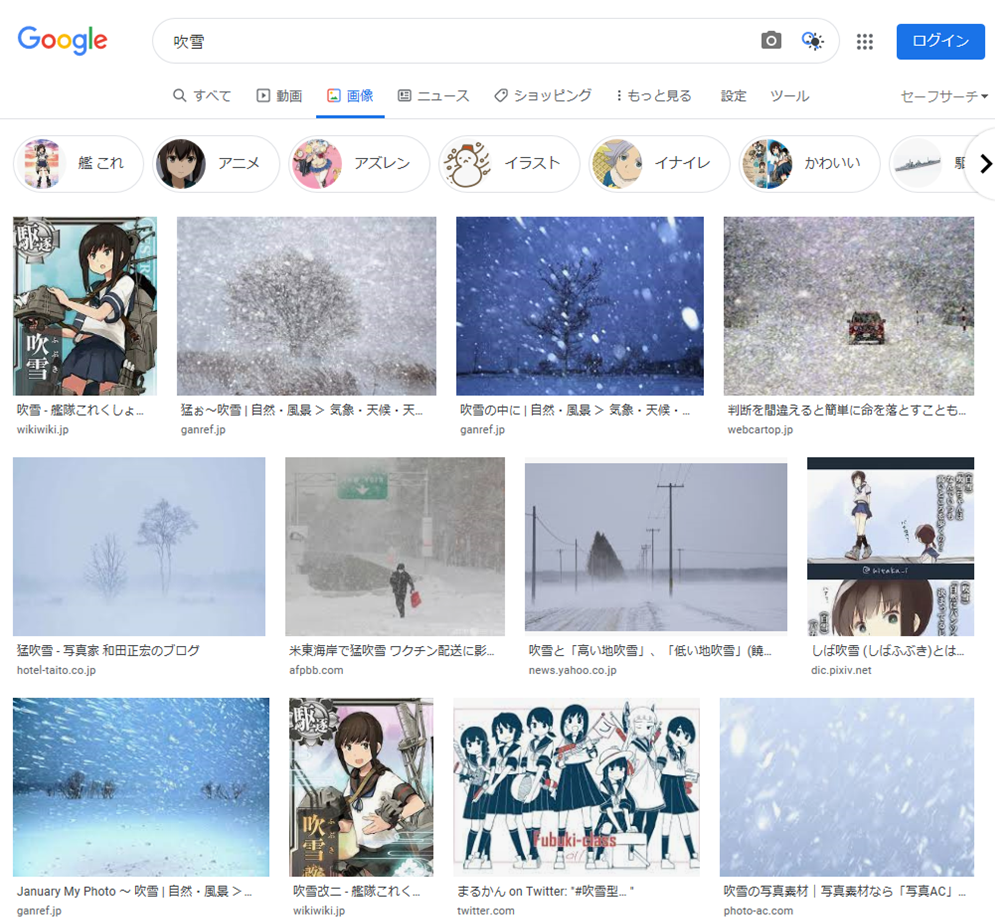
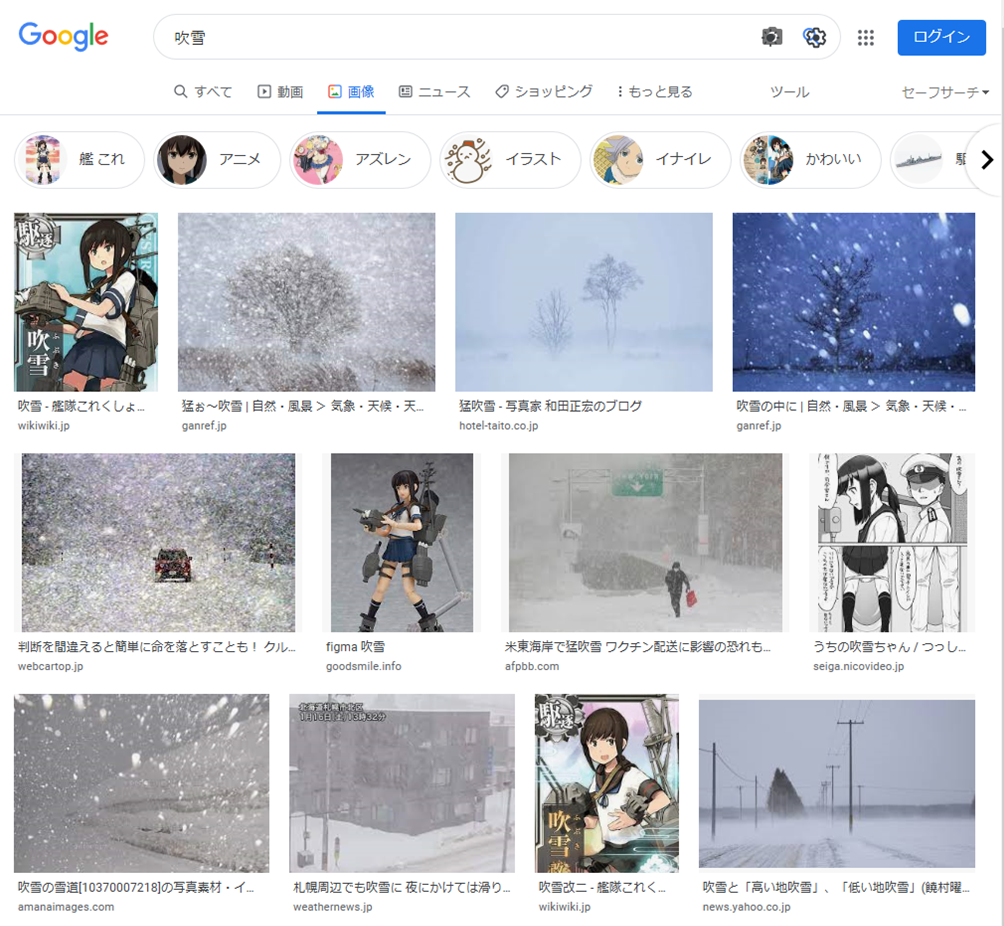


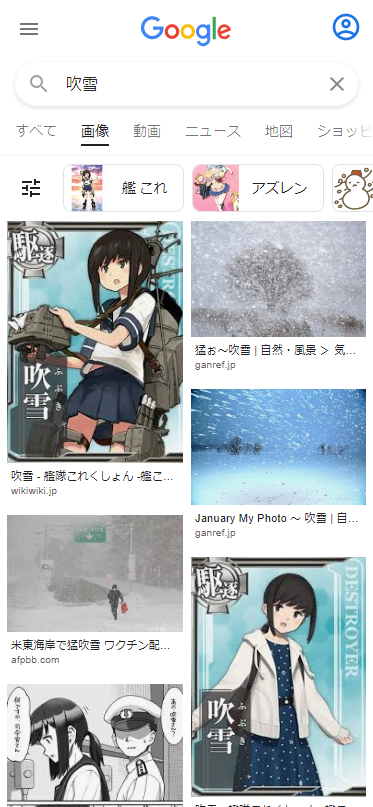
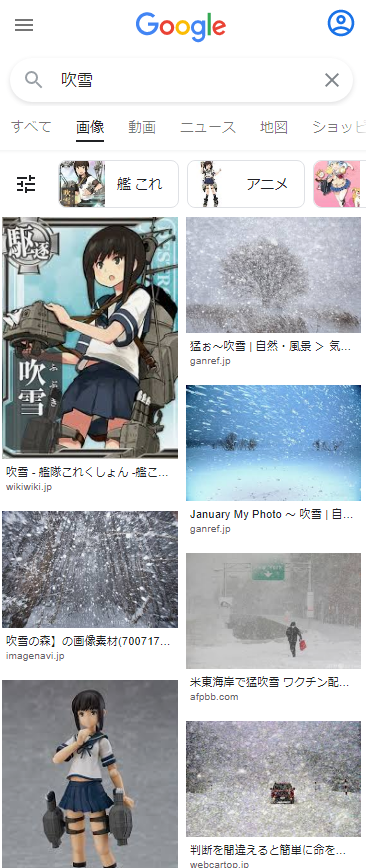
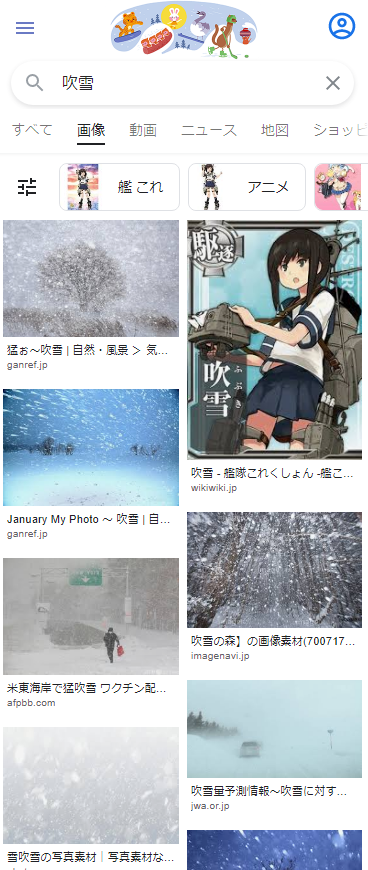
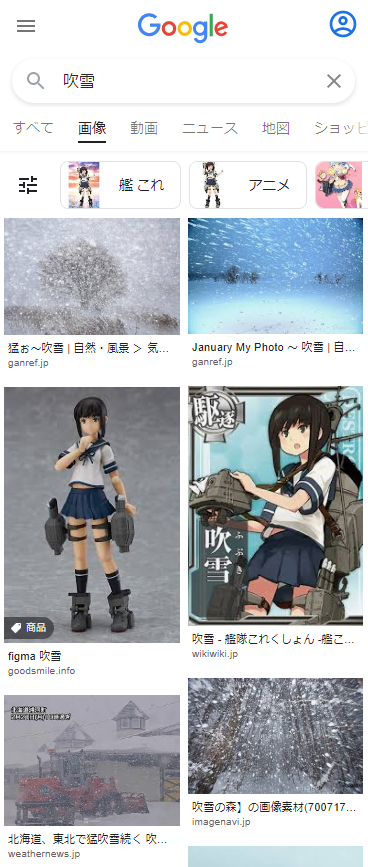
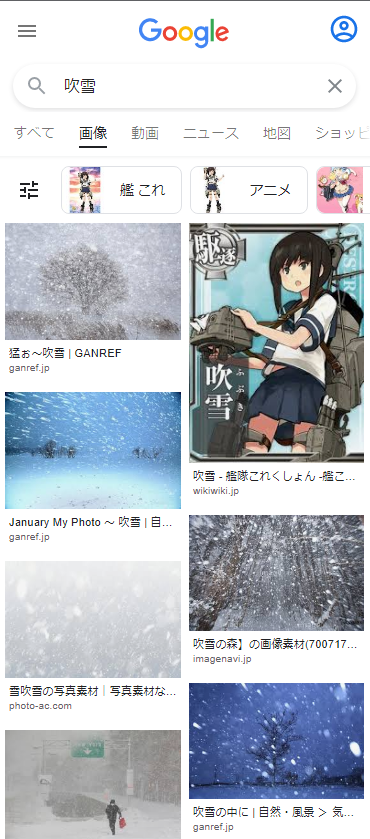
ということで、徐々に変化した感じでした。
Google画像検索[吹雪]。いつの間にかに大半が自然の吹雪になってた。いつからだろ。 pic.twitter.com/YpiyC9K2Xf
— 辻正浩 | Masahiro Tsuji (@tsuj) 2022年4月6日
ということで調べてみました。
ということで、徐々に変化した感じでした。
検索エンジンは進化を続けています。その中で、特にここ数年で進化が著しいのは「意味」の認識だと私は考えます。
文字列一致を中心にした検索エンジンでは今のインターネットに対応出来ませんので、今日の検索エンジンは、検索された検索語句やWebページの意味を識別した上で検索結果を作っています。
その意味認識の進化の例としておもしろい検索結果が確認できましたのでご共有です。
これは[対馬]の検索結果の3週間での変化です。

これはGoogleの意味認識の異様な精度を表すものとして興味深いのですが、複雑ですので少し解説を書いてみます。
「艦隊これくしょん」というゲームがあります。旧日本軍の軍艦を擬人化したキャラクターによるシミュレーションゲームです。
このゲームで11月17日から始まったイベント「捷号決戦!邀撃、レイテ沖海戦(前篇)」で、新キャラクター「対馬」が登場しました。

多くの人にとって「対馬」というと長崎県の対馬でしょう。[対馬]という検索で求められる主な情報も地名としての対馬の情報ばかりだったはずです。
しかし11/14に艦これの対馬実装が発表されてからは、このキャラクターや元ネタとなる船の対馬の情報を求める検索が増えました。シンプルだった情報のニーズが、複雑になったのです。
さらにその複雑さに輪をかける事として「対馬」という船は3隻ありました。
今回の艦隊これくしょん登場キャラ「対馬」は1942年に起工した海防艦対馬のキャラクターですが、他に1901年に起工した「防護巡洋艦対馬」と1990年に起工された海上自衛隊の「掃海艦つしま」があったのです。
そしてこの3隻で「海防艦対馬」だけはWikipediaにページが存在していません。これは対馬_(曖昧さ回避)ページですが

このように、多くの人が情報を求めるようになった「海防艦対馬」はページが存在していなかったのです。(12/5 4:30追記:海防艦対馬のページは11/24に新規作成されていたようです。作成されたばかりでGoogleが評価していなかったようですね)
Googleの意味/エンティティ判断には、Wikipediaが大きな影響を与えていると推測されます。そのWikipediaには正解が無い状態で情報のニーズだけが増えた、という特殊な状況が今回発生したのです。
この同じ名前の2隻は70-100年前の船で、情報の多くは失われてあまり伝わっていませんし、インターネット上にもあまり記載されていません。その同じ名前で検索がされたときに、どちらの船の情報が求められているかを判断する、というのは、極めて難しいはずですが、Googleはどのように処理したのでしょうか。
この状況での検索結果の変化が冒頭で出したものです。
実際の検索結果には、艦隊これくしょんのキャラクター紹介ページが入ってきましたが、問題は右カラムのパネルを見てください。

11/17にキャラクターが実装されて検索ニーズが増えた結果、一度はWikipediaページを元に「対馬(防護巡洋艦)」を表示しますが、その後数日で、海防艦対馬の英訳「Japanese Escort Ship Tsushima」を表示しました。
ここが英語になっているのは、日本語の「海防艦対馬」のページは12/4現在存在しませんが、英語版やフィンランド語、インドネシア語、ペルシャ語のページは存在していて、英語版を情報元として使ったからだと考えられます。
対馬という検索が増えたもののその意味を明確に言語化するページが存在しないため、英語版ページを表示したということになります。
対馬(海防艦)と対馬(防護巡洋艦)は全く違う船ですが、多くの人にはその違いはわからないでしょう。にも関わらず、[対馬]という検索の意味がどちらを示しているのか、Googleはアルゴリズムで判断できていると言えます。
通常、日本語検索のこの部分には英単語は出づらいものです。曖昧な意味認識でしたら何も出さないか、Wikipediaにページがある防護巡洋艦を出し続けていたはずですが、Googleは明らかに防護巡洋艦ではない、と判別できたのでしょう。
Wikipediaを参考にしていることは確かですが、Wikipediaだけを重視するわけではなく色々なデータを元に判断が出来ていると言えます。
このように判断できた理由は、シンプルなものではないはずです。掛け合わせて検索されるキーワードの変化や、世界中のWebページに発生する文言などを元に総合的に検索キーワードとWebページの意味を判断をしていると思われます。
この意味認識は右のパネルだけではなく実際の検索結果にも大きく影響をしています。そのように高度な意味の認識を元に検索意図に合う情報を検索者に届けているのが現在の検索エンジンです。
普通に検索していると、知りたい情報が表示されるのが当たり前のように思えてきます。ただ今回のように裏では非常に高度な処理が行われていることも多いです。
このような高度な意味の認識はGoogle以外の検索エンジンは出来ていませんし、3~4年前のGoogleでも出来ていなかったはずです。
最近、検索結果に色々な問題があることが良く言及されるようになりましたし、それはその通りと思います。ただますます複雑になるインターネットの中で、着実に検索エンジンも進化を続けていることも確かと思います。
価値と問題の両方を把握していきたい、と私は思います。
Googleの検索結果でECで購入した商品がGoogleの検索結果に表示するテストをしているのを確認しました。
(2016/1/14追記:Gmailを使っていて直近でEC利用した人の多くに出ているようです。これはテストではなく全体に反映された仕様のようですね。)

ECで購入した後にGmailで受信した購入データをGoogleが解釈して、そのGmailのGoogleアカウントでログインしているときだけ表示されているようです。

最初にこのように、
「Gmailに最近購入した商品に関する情報があります。」
「この結果は自分だけが閲覧できます。」
という表示とOKボタンが現れます。
OKボタンを押すと、商品が表示されます。

スマホでも同様に表示されます。

直近で購入したECはヨドバシカメラとAmazonだけですが、この2つでは表示されました。
Amazonでもこのように表示されます。

なお、ECショップ名だけではなく、購入した商品名や型番で検索しても表示されます。


商品名部分はリンクになっていて、そこをクリックするとなぜか[注文(2016/1/14)]というキーワードの検索結果に飛ばされます。

これはどう考えても有益な検索結果ではありませんし、おそらくはGoogleのミスなのでしょう。本当は、Gmailにリンクする仕様なのでしょうか?
この仕様は、ユーザとしてで非常に便利なものではないと思いますし、SEOとしても特になにか考える事もないとは思います。
しかし、二重買い防止にもなるでしょうし、「お店のサイトに行って注文した商品の状況を知りたい」と店名で検索することは多いのでそういう時にはとても便利ですね。
こういう仕様はPC共有時にさまざまな悲喜劇が考えられますが、今のGoogleの仕様を考えますと自分のIDでログインしたPCを人に貸すべきではないですし、それを防ぐためのChromeのユーザ切り替え等も便利になりました。
もっと検索結果が便利になりつつ、変なトラブルをおこなさないように注意して使っていきたいものですね。
(以下2016/1/14 11時追記)
この仕様はECだけではなくいろいろと拡大しているようですね!
エアラインでも出てきた。cc: +辻正浩 https://t.co/vJKddhfUZ6 pic.twitter.com/ZtbffLw63t
— Kenichi Suzuki; 鈴木謙一 (@suzukik) 2016, 1月 14
@tsuj こんにちは。参加イベント情報も出るんですよー。ご参考までに。 pic.twitter.com/1UWpDzC81k
— Tsuyoshi Yonemoto (@yoneapp) 2016, 1月 13
このブログで、body要素内にnoindexを入れる実験をしていたのですが、3週間たったので終了。
body要素内にnoindexを入れてから3週間、上記記事はインデックスされなかったので、やはり確実に効いていたのかと。
やはり以前と変わらず、既存インデックスはnoindexの付与だけで早々に既存インデックスが消えることは無いですね。3週間待って、75から56に減っただけでした。

早々に消したければ、noindexの付与のみではなく、Search Consoleからの「URLの削除」が必要です。
こんな実験をやるようなブログですので急いでインデックス回復させる必要もないのですが、一応トップページのFetch as GoogleとXMLsitemapの再送信を完了。
はてなブログのXMLサイトマップは、Googleが推奨する方法のrobots.txtでの自動送信されているので通常はsitemapを意識する必要はありませんが、このようなイレギュラーなときは再送信するとほんの少しは早くなるかと思います。まぁfetchのほうが確実ですが。
noindexはbody要素内でも有効という事、知らなかった。
どうしてなんだろう?canonicalなど、head要素でしか通用しない部分はあるのに、どうしてnoindexは全体で反映されているんだろう?
しかし、これが本当に反映されるのかは試さないとわからないので、ひとまずこのブログの全ページのbody内にnoindexを加えてみました。
どうなるのか確認。
検索結果で画像検索結果がブレンドされる場合、1件としてカウントされるように昨年秋に変更されていたことにいまさら気づきました。
検索結果1ページの10件は、表示される内容によって1件としてカウントされるかが変わりますが、画像検索結果は昨年9月まではカウントされなかったはずです。それが10月からカウントされるようになっています。
おそらくは2014年10月5日~10月9日の間の変更と思われます。
これが2014年10月5日のGoogle[春雨 レシピ]の検索結果。

そしてこちらが10月9日の検索結果。

いくつかの検索語句の記録を見ましたが、どれもこの間で変わっているようです。
私も今頃気づきましたように、トラフィック影響はほとんど無いはずですが一応の記録です。
Googleが検索の仕組みを説明するために2013年3月に公開した英語版インフォグラフィックがあります。この一部分が8月下旬に更新されていました。
海外SEO情報ブログのインフォグラフィックの解説を書かれた記事をお借りして見ますと、最初の画面はこうなっていました。Googleが30Trillion、30兆ものページを扱っているという話ですね。

これが、今はこう変わっています

倍増!?
30 trillion から60 trillionになっています。
実際にも相当増えているのでしょうし、計算方法の変化とかもあるでしょうけど、流石に半年経たずに倍増は速すぎるような……
ちなみにHTMLソースを見ると、idは「thrty_trillion」のままになっているなど、変更前の名残が残っています。

まぁ、30兆でも60兆でも、数え切れない途方も無い数のページを扱っていることは確かです。
このGoogleのインフォグラフィックはなかなか面白い内容です。もし見ていない方がいましたら、ぜひご覧ください。